XML se dnes používá téměř všude a je na něm postavena celá řada dalších formátů. Samotné XML se používá jako prostředek při předávání nebo uchovávání nejrůznějších typů dat. Můžeme do něj uložit prakticky jakoukoliv strukturu informací. Nebudu se zde do detailů rozepisovat o tom, co XML je a jak přesně vypadá, pokud toho o XML moc nevíte, podívejte se online na přednášku Michala Altaira Valáška, zejména na první díl.
S XML můžeme potřebovat pracovat v mnoha různých případech - pokud si chcete napsat RSS čtečku, budete potřebovat XML číst, pokud chcete napsat aplikaci, která volá nějakou webovou službu, i tam se XML jistě využije (i když zrovna tady se s ním zaobírat moc nemusíte), pokud používáte ve svých aplikacích Application Settings, tak i ty se ukládají do XML. A to už vůbec nemluvím o aplikacích webových, kde je na XML postavené skoro vše.
Jak XML vypadá?
Protože se dnes budeme učit XML číst a zapisovat, budeme potřebovat vzorový dokument. Na něm ukážu, jak XML může vypadat.

Prologue je nepovinné záhlaví XML dokumentu. Hodnota version je vždy 1.0, jiná verze formátu XML neexistuje, dále můžeme uvést kódování národních znaků. Pokud prologue není uveden, musí být dokument v kódování UTF-8. Pokud prologue v dokumentu je, musí být vždy hned na začátku.
Begin tag a end tag (česky asi počáteční tag a koncový tag, slovo tag se občas překládá jako značka). Tagy popisují strukturu dokumentu, mají svůj a musí být uzavřeny ve špičatých závorkách, např. <objednavky>. Koncový tag se od počátečního pozná tak, že před názvem má ještě lomítko - </objednavky>. Pokud mají tagy stejný název a jsou stejně zanořeny, patří k sobě. Pokud bychom měli tedy třeba dokument <a><a><a></a></a></a>, tak k sobě patří 3. a 4. tag, dále 2. a 5. a také 1. a 6. Nikdy nesmí dojít ke křížení tagů - dokument <a><b></a></b> je nepřípustný, tag </b> musí být před </a>.
Elementem nazýváme celou oblast od počátečního do příslušného koncového tagu, na obrázku jsou vyznačeny dva elementy obdélníkem. Element může uvnitř mezi počátečním a koncovým tagem obsahovat text nebo další elementy.
Někdy ještě používáme atributy, které zapisujeme dovnitř počátečního tagu. Každý atribut může mít svoji hodnotu, která musí být uzavřena v úvozovkách.
XML má ještě několik dalších pravidel, je case-sensitive, to znamená, že záleží na velikosti písmen v názvech - <a> není stejné jako <A>, to samé platí i pro atributy. Celý dokument tvoří vždy jeden kořenový element, který obsahuje všechny další elementy. V dokumentu na obrázku je to element objednavky.
Kdy XML použít?
Nejtypičtějším příkladem, kdy budete opravdu XML potřebovat přečíst a zapisovat, je asi nějaké jednoduché datové úložiště. Pokud budete psát nějakou aplikaci, kde si musíte uchovávat nějakou jednoduchou databázi, asi sáhnete po formátu XML. Nemusíte instalovat žádné databázové knihovny, protože .NET framework má velmi dobré nástroje pro práci s XML.
Je třeba si ale také uvědomit, že ne na vše se XML hodí. Pokud má XML dokument velikost řádově desítek až stovek kilobajtů, je vše v pořádku, s většími dokumenty se ale pracuje pomalu. Pokud máte dat hodně, je rozhodně na místě použít databázi, pokud jich není zas až tak moc, XML se hodí.
Pokud chcete ukládat data se složitou strukturou, je XML opět pravděpodobně nejlepší možná volba. Zkuste se ale zamyslet, jestli by se data nedala uložit např. do INI souboru. Je naprosto zbytečné ukládata do XML něco takového:
<data>
<cislo cislo="1" slovy="jedna" />
<cislo cislo="2" slovy="dvě" />
<cislo cislo="3" slovy="tři" />
<cislo cislo="4" slovy="čtyři" />
<cislo cislo="5" slovy="pět" />
<cislo cislo="6" slovy="šest" />
...
</data>
Pro tenhle účel se daleko více hodí právě INI soubor, v XML máte kolem všeho spoustu zbytečných znaků, dokument je tak větší a jeho zpracování pomalejší.
1=jedna
2=dvě
3=tři
4=čtyři
5=pět
6=šest
...
Dva různé přístupy pro práci s XML
S XML můžeme v praxi pracovat několika způsoby. Zdaleka nejhorší řešení je zkoušet číst XML ručně pomocí tříd StreamReader a StreamWriter. XML sice má poměrně jednoduchá pravidla, ale může vás cestou potkat mnoho záludností, a navíc napsaní takového XML parseru není zrovna věc, která by se dala běžně zvládnout za půl hodiny.
.NET framework nám nabízí několik nástrojů, které s XML umí pracovat. Každý z nich se hodí v jiné situaci. Třída XmlDocument používá přístup DOM (Document Object Model). Celý XML dokument si načte do paměti a udělá si z něj jakýsi strom. U malých a středních XML dokumentů je to skvělé, můžete v dokumentech prohledávat, dělat na nich XPath dotazy (podobně jako třeba databázi prohledáváte pomocí dotazů v jazyce SQL). Navíc dokument můžete upravit a pak jej zavoláním metody Save uložit zpět do souboru. Pokud tedy potřebujete načíst XML dokument a případně v něm něco málo změnit a uložit zpět, je výhodné použít třídu XmlDocument.
Pokud potřebuji XML dokument vytvořit z ničeho, pak je XmlDocument sice možné, ale pomalé a neobratné řešení. Daleko lepší je použít třídu XmlTextWriter, která je určena pro snadné a rychlé generování dokumentů XML. Pak ještě existuje třída XmlTextReader, která se hodí, pokud potřebujeme dokument jen projít od začátku dokonce a vytáhnout z něj několik hodnot, popřípadě pokud je dokument velký a nechceme jej celý načítat do paměti, což třída XmlDocument nutně udělat musí.
Načtení XML dokumentu s objednávkami
Jako ukázkový příklad si v tomto díle napíšeme jednoduché zobrazovátko na náš původní ukázkový dokument. Tento dokument si stáhněte a přidejte do nového projektu Windows Application:
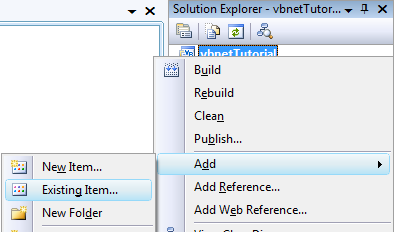
Souboru nastavte vlastnost Copy To Output Directory na hodnotu Copy Always:
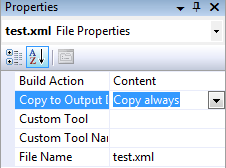
Tím zajistíme, že se nám soubor zkopíruje do složky s výsledným EXE souborem a budeme jej moci z aplikace využít. Soubor ještě v okně Solution Explorer přejmenujte na název data.xml.
Na formulář přidejte komponenty podle obrázku:
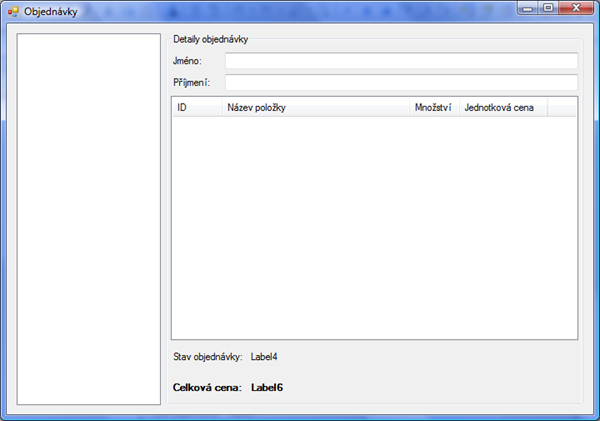
Boční komponenta je ListBox a seznam v detailech objednávky je ListView. Ostatní komponenty jsou doufám jasné, na jméno a příjmení máme TextBoxy. Komponenty pojmenujte názvy listBoxObjednavky, textBoxJmeno, textBoxPrijmeni, listViewPolozky, labelStav a labelCena. Seznamu položek nastavte hodnotu vlastnosti View na hodnotu Details a v kolekci Columns vytvořte 4 sloupečky taktéž podle obrázku.
Načtení XML dokumentu do paměti a vytažení seznamu objednávek
Všechny funkce pro práci s XML se nacházejí ve jmenném prostoru System.Xml. Abychom jej před názvy tříd nemuseli pořád vypisovat, naimportujeme si jej. Úplně nahoru do souboru s kódem formuláře přidejte tento řádek:

Imports System.Xml

using System.Xml;
Poklepejte na formulář, aby se nám otevřela procedura události Form1_Load. Nad ní přidejte tuto deklaraci:
Dim doc As New XmlDocument()
XmlDocument doc = new XmlDocument();
Tím jsme vytvořili nový objekt XmlDocument, do kterého nyní načteme v proceduře Form1_Load náš XML soubor. Dovnitř procedury Form1_Load tedy přidejte tento kód:
'načíst XML soubor
doc.Load("data.xml")
'projít všechny elementy "objednavka" a přidat je do seznamu
For Each n As Xml.XmlNode In doc.SelectNodes("/objednavky/objednavka")
listBoxObjednavky.Items.Add("Objednávka č. " & n.Attributes("id").Value)
Next
//načíst XML soubor
doc.Load("data.xml");
//projít všechny elementy "objednavka" a přidat je do seznamu
foreach (XmlNode n in doc.SelectNodes("/objednavky/objednavka"))
listBoxObjednavky.Items.Add("Objednávka č. " + n.Attributes["id"].Value);
Zavoláním metody Load XML soubor jednoduše načteme do paměti. Náš objekt doc, tedy instance třídy XmlDocument, si XML soubor přečte a vytvoří s jakýsi virtuální strom elementů který si můžete představi např. takto:
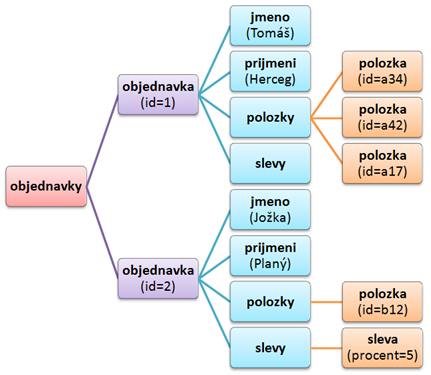
A jak funguje naše vybírání objednávek? Projdeme všechny objekty XmlNode (každý XmlNode je vlastně jeden obdélníček na obrázku), které vyhovují XPath dotazu "/objednavky/objednavka". Tento dotaz vybere všechny elementy objednavka, které najde na cestě /objednavky, tedy uvnitř kořenového elementu objednavky. O jazyku XPath si můžete přečíst v tomto článku ze serveru Interval.cz, jen samotný jazyk XPath by vydal nejméně na samostatný článek.
Nám z něj bude stači úplné minimum - /objednavky/objednavka začne hledat od kořenového elementu, protože dotaz začíná lomítkem. Najde element objednavky, a tak se podívá dovnitř a vybere všechny elementy objednavka, které obsahuje. Hledá ale jen ve fialových elementech, do větší hloubky už nesahá. Kdyby tedy byl na obrázku ještě element objednavka někde ve třetí úrovni, tento dotaz jej nevybere.
Náš cyklus For Each tedy projde všechny objekty, které nám vybrala metoda doc.SelectNodes s příslušným XPath dotazem předaným v parametru. Pro každý z těchto objektů XmlNode se provede vnitřek vyklu, právě procházený objekt bude vždy v proměnné n. Do seznamu listBoxObjednavky tedy přidáme novou položku s textem Objednávka č. a hodnotou atributu id právě procházeného elementu, kterou zjistíme z kolekce n.Attributes("název").Value. To je celé načtení seznamu objednávek.
Vypsání detailů objednávky
Vypsání detailů objednávky už bude jenom obměna toho, co jsme již dělali. Poklepejte na seznam objednávek a do procedury události listBoxObjednavky_SelectedIndexChanged vložte tento kód:
'pokud není nic vybráno, ukončíme proceduru
If listBoxObjednavky.SelectedIndex = -1 Then Exit Sub
'pracujeme s objednávkou s indexem vybrané položky
With doc.SelectNodes("/objednavky/objednavka")(listBoxObjednavky.SelectedIndex)
'načíst jméno a příjmení
textBoxJmeno.Text = .SelectSingleNode("jmeno").InnerText
textBoxPrijmeni.Text = .SelectSingleNode("prijmeni").InnerText
'načíst všechny položky objednávky
Dim cena As Double = 0
listViewPolozky.Items.Clear() 'vyprázdnit seznam položek
For Each n As Xml.XmlNode In .SelectNodes("polozky/polozka")
'vytvořit položku ListView
Dim item As New ListViewItem()
item.Text = n.Attributes("id").Value 'nastavit hodnotu prvního sloupce
item.SubItems.Add(n.Attributes("nazev").Value) 'nastavit hodnotu druhého sloupce
'nastavit hodnotu třetího sloupce a převést si ji na číslo, budeme jej dále potřebovat
Dim mnozstvi As Integer = CInt(n.Attributes("mnozstvi").Value)
item.SubItems.Add(mnozstvi)
'nastavit hodnotu čtvrtého sloupce a zformátovat ji jako měnu
Dim cenaZaKus As Double = CDbl(n.Attributes("cenaZaKus").Value)
item.SubItems.Add(cenaZaKus.ToString("c"))
'přidat vytvořenou položku do seznamu
listViewPolozky.Items.Add(item)
'přičíst cenu do celkové ceny
cena += cenaZaKus * mnozstvi
Next
'načíst stav objednávky a zobrazit celkovou cenu zformátovanou jako měnu
labelStav.Text = .Attributes("stav").Value
labelCena.Text = cena.ToString("c")
End With
//pokud není nic vybráno, ukončíme proceduru
if (listBoxObjednavky.SelectedIndex == -1) return;
//pracujeme s objednávkou s indexem vybrané položky
XmlNode objednavka = doc.SelectNodes("/objednavky/objednavka")[listBoxObjednavky.SelectedIndex];
//načíst jméno a příjmení
textBoxJmeno.Text = objednavka.SelectSingleNode("jmeno").InnerText;
textBoxPrijmeni.Text = objednavka.SelectSingleNode("prijmeni").InnerText;
//načíst všechny položky objednávky
double cena = 0;
//vyprázdnit seznam položek
listViewPolozky.Items.Clear();
foreach (XmlNode n in objednavka.SelectNodes("polozky/polozka"))
{
//vytvořit položku ListView
ListViewItem item = new ListViewItem();
//nastavit hodnotu prvního sloupce
item.Text = n.Attributes["id"].Value;
//nastavit hodnotu druhého sloupce
item.SubItems.Add(n.Attributes["nazev"].Value);
//nastavit hodnotu třetího sloupce a převést si ji na číslo, budeme jej dále potřebovat
int mnozstvi = Convert.ToInt32(n.Attributes["mnozstvi"].Value);
item.SubItems.Add(mnozstvi.ToString());
//nastavit hodnotu čtvrtého sloupce a zformátovat ji jako měnu
double cenaZaKus = Convert.ToDouble(n.Attributes["cenaZaKus"].Value);
item.SubItems.Add(cenaZaKus.ToString("c"));
//přidat vytvořenou položku do seznamu
listViewPolozky.Items.Add(item);
//přičíst cenu do celkové ceny
cena += cenaZaKus * mnozstvi;
}
//načíst stav objednávky a zobrazit celkovou cenu zformátovanou jako měnu
labelStav.Text = objednavka.Attributes["stav"].Value;
labelCena.Text = cena.ToString("c");
Nejprve zkontrolujeme, jestli index vybrané položky není -1. V takovém případě to znamená, že není vybraná položka žádná, a nechceme nic dělat. Pak si najdeme element naší objednávky, se kterou chceme pracovat. Opět si najdeme všechny objednávky pomocí SelectNodes a vybereme z nich jen tu s indexem, jaký má vybraná položka v seznamu objednávek. Indexy seznamu i objednávek jsou číslovány od nuly, takže položka 0 v seznamu odpovídá první objednávce, která má index 0. Možná si řeknete, že je zbytečné vybírat všechny objednávky a pak z nich vytáhnout jen jednu, máte pravdu. Místo toho by šlo použít metodu SelectSingleNode a předat jí "chytřejší" XPath dotaz (konkrétně "/objednavky/objednavka[1]", kde číslo v závorkách udává pořadí elementu, ale číslované od nuly), ale nechci vám plést hlavy s XPath jazykem.
Z aktuálního elementu vytáhneme teď už pomocí SelectSingleNode elementy jmeno a prijmeni a jejich hodnoty InnerText (text, který obsahují uvnitř) přiřadíme do příslušných TextBoxů. Dále musíme projít všechny položky objednávky a přidat je do seznamu listViewPolozky. Přitom musíme počítat celkovou cenu celé objednávky, kterou do XML dokumentu neukládáme, ale v aplikaci ji chceme zobrazit. Před přidáváním položek seznam vyprázdníme, aby nám v něm nezůstávaly položky z objednávek zobrazených dříve.
Pak již následuje nám známý For Each cyklus, kterým projdeme všechny elementy polozky uvnitř elementu polozky. Metodu SelectNodes nevoláme na celý dokument, ale jen na element aktuální objednávky, takže nám tato metoda vybere jen položky z naší objednávky, což přesně potřebujeme.
Pro každý element polozka pak již jen vytvoříme novou položku seznamu ListView, tedy instanci třídy ListViewItem. Nastavíme jí textové hodnoty ID a název položky, dále pak si zjistíme množství a cenu za kus, zapíšeme je do sloupců v seznamu a přičteme do proměnné cena, kterou jsme si před cyklem vynulovali. Položku přidáme samozřejmě do seznamu listViewPolozky, to byste už ale měli znát.
Nakonec načteme stav objednávky, který je uložen v atributu stav elementu objednavka, a celkovou cenu zapíšeme do labelu labelCena. To je celé načtení detailů objednávky.
Úpravy XML dokumentu
Pokud byste chtěli dokument trochu upravit a znovu uložit, je to velmi jednoduché. Ukazovat to nebudu, zvládnete to sami. Stačí, když změníte hodnoty atributů nebo nastavít hodnoty InnerText a pak zavoláte doc.Save. Dokument se uloží včetně změn, které jste provedli.
To byla tedy třída XmlDocument, viděli jste, že dokument načteme na začátku a pak v něm můžeme hledat a pracovat s jeho elementy a atributy. Někdy ovšem potřebujeme dokument vytvořit "z vody", resp. nemáme nic. Lze to i s pomocí této třídy. Zavoláním doc.CreateElement("test") například vytvoříme element test, kterému můžeme nastavit atributy. Každý element v dokumentu má navíc metody AppendChild, InsertBefore či InsertAfter, kterým můžeme nově vytvořený element předat, a ony jej začlení do kolekce svých potomků na určené místo. Pokud potřebujeme přidat několik položek do existujícího XML dokumentu, určitě se nám tyto metoda vyplatí.
Vygenerování XML dokumentu od základu
Do naší aplikace bychom mohli přidat další tlačítko, které by vygenerovalo seznam objednaných položek pro našeho subdodavatele. Subdodavatel, který nám zboží poskytuje, požaduje objednávku například v tomto formátu:
<objednavka>
<zakaznik>3567</zakaznik>
<polozky>
<polozka id="a34" mnozstvi="1" />
<polozka id="a42" mnozstvi="4" />
<polozka id="a17" mnozstvi="1" />
<polozka id="b12" mnozstvi="1" />
</polozky>
</objednavka>
Jak tedy něco takového vygenerovat? Jistě si řeknete, že není problém použít StreamWriter a vypsat něco takového ručně. Máte pravdu, pro jednoduché struktury je to přijatelné řešení, ale není to tak hezké. A pokud byste nedejbože strukturu dokumentu chtěli v budoucnu změnit (celé to vnořit do elementu objednavky), může to dát dost práce, pokud se ještě namáháte s odsazováním.
Můžeme ale použít třídu XmlTextWriter, která je pro generování XML dokumentů určená. Přidejte si tedy do aplikace tlačítko Generovat objednávku pro subdodavatele a do příslušné procedury události napíšeme kód, který nám vygeneruje objednávku pro subdodavatele. Ještě než začneme, zdůrazním jeden detail - musíme počítat s tím, že dva naši zákazníci si objednali stejné zboží. Subdodavatel jistě nebude rád, když budeme chtít 3 smetáky a rozdělíme mu to na 2 nebo 3 položky. Vytvoříme si tedy objekt Dictionary (slovník), který si bude pamatovat id položek a požadovaná množství. Pak projdeme všechny objednávky a všechny jejich položky a budeme je přidávat do slovníku. Pokud tam položka s takovým id už bude, přičteme k jejím množství hodnotu z aktuální položky, pokud tam nebude, tak ji přidáme. Nakonec projdeme celý slovník a vypíšeme všechny položky, tím ale máme zajištěno, že více kusů jednoho druhu zboží se nerozdělí jako do více položek.
Tento kód tedy přidejte do procedury události tlačítka:
'projít všechny položky objednávek a zjistit celková množství pro každý druh zboží
Dim dic As New Dictionary(Of String, Integer) 'vytvoříme slovník ID položky - počet kusů
'projít všechny položky a zjistit celkové počty kusů pro jednotlivé druhy zboží
For Each n As Xml.XmlNode In doc.SelectNodes("/objednavky/objednavka/polozky/polozka")
Dim id As String = n.Attributes("id").Value
Dim mnozstvi As Integer = CInt(n.Attributes("mnozstvi").Value)
If dic.ContainsKey(id) Then 'pokud už tento typ zboží v objednávce je, přičteme množství
dic(id) += mnozstvi
Else 'tento druh zboží ještě v objednávce není, přidáme jej
dic.Add(id, mnozstvi)
End If
Next
'vygenerovat XML dokument
Dim w As New Xml.XmlTextWriter("objednavka.xml", Nothing)
w.Formatting = Xml.Formatting.Indented 'nastavit odsazování
w.WriteStartDocument()
'zapsat element "objednavka"
w.WriteStartElement("objednavka")
'zapsat element "zakaznik" a dovnitř jako text ID zákazníka přidělené subdodavatelem
w.WriteElementString("zakaznik", "3567")
'zapsat element "polozky"
w.WriteStartElement("polozky")
'zapsat všechny položky
For Each id As String In dic.Keys 'projít všechna ID ve slovníku
w.WriteStartElement("polozka")
w.WriteAttributeString("id", id) 'zapsat ID zboží
w.WriteAttributeString("mnozstvi", dic(id)) 'zapsat množství ze slovníku
w.WriteEndElement() 'uzavřít element "polozka"
Next
'dokončit dokument (neuzavřené elementy se automaticky uzavřou samy)
w.WriteEndDocument()
w.Close()
System.Diagnostics.Process.Start("objednavka.xml")
//projít všechny položky objednávek a zjistit celková množství pro každý druh zboží
Dictionary<string, int> dic = new Dictionary<string, int>(); //vytvoříme slovník ID položky - počet kusů
//projít všechny položky a zjistit celkové počty kusů pro jednotlivé druhy zboží
foreach (XmlNode n in doc.SelectNodes("/objednavky/objednavka/polozky/polozka"))
{
string id = n.Attributes["id"].Value;
int mnozstvi = Convert.ToInt32(n.Attributes["mnozstvi"].Value);
if (dic.ContainsKey(id))
{
//pokud už tento typ zboží v objednávce je, přičteme množství
dic[id] += mnozstvi;
}
else
{
//tento druh zboží ještě v objednávce není, přidáme jej
dic.Add(id, mnozstvi);
}
}
//vygenerovat XML dokument
XmlTextWriter w = new XmlTextWriter("objednavka.xml", null);
w.Formatting = Formatting.Indented; //nastavit odsazování
w.WriteStartDocument();
//zapsat element "objednavka"
w.WriteStartElement("objednavka");
//zapsat element "zakaznik" a dovnitř jako text ID zákazníka přidělené subdodavatelem
w.WriteElementString("zakaznik", "3567");
//zapsat element "polozky"
w.WriteStartElement("polozky");
//zapsat všechny položky
foreach (string id in dic.Keys)
{
//projít všechna ID ve slovníku
w.WriteStartElement("polozka");
w.WriteAttributeString("id", id); //zapsat ID zboží
w.WriteAttributeString("mnozstvi", dic[id].ToString()); //zapsat množství ze slovníku
w.WriteEndElement(); //uzavřít element "polozka"
}
//dokončit dokument (neuzavřené elementy se automaticky uzavřou samy)
w.WriteEndDocument();
w.Close();
System.Diagnostics.Process.Start("objednavka.xml");
Na začátku jsme si tedy vytvořili slovník Dictionary (Of String, Integer). Tento slovník nedělá nic jiného, než že si ke každému ID typu String, které mu dáme, pamatuje jedno číslo. Projdeme všechny položky ze všech objednávek a vytáhneme si z nich příslušná id a množství. Pokud už ve slovníku dotyčné id je, znamená to, že někdo před námi si už ten smeták objednal a počet smetáků z aktuální objednávky tedy přičteme k těm smetákům, které už máme zpracované, abychom nevytvářeli duplicitní položky. Pokud smetáky ještě nikdo nechtěl, přidáme je do našeho slovníku. Slovník je pro nás jenom nástroj, který nám umožňuje jednoduše zjistit, jestli někdo už smetáky chtěl, a kolik jich bylo. Na konci se dozvíme, kolik celkem jich budeme potřebovat.
Pak již vytvoříme nový objekt XmlTextWriter, předáme mu název souboru a kódování češtiny (necháme tam výchozí, nic neměníme, takže předáme Nothing). Dále nastavíme vlastnost Formatting na hodnotu Indented, aby nám XmlTextWriter elementy hezky odsazoval. Kdybychom tuto vlastnost nenastavili, nacpaly by se všechny elementy na jeden řádek, což není v rozporu s pravidly XML dokumentů, ale není to přehledné pro nás. Pak jen stačí zavolat WriteStartDocument a můžeme začít.
Nyní budeme dokument stavět, stejně jako kdybychom jej psali ručně. WriteStartElement napíše počáteční tag zadaného názvu, WriteElementString napíše celý element s daným názvem a textem uvnitř, např. WriteElementString("a", 13) napíše toto: <a>13</a>. Napíše se tedy jak počáteční, tak koncový tag, a mezi ně požadovaný text. Dále máme metodu WriteAttributeString, která k naposledy zapsanému tagu připíše atribut a jeho hodnotu. Pokud tedy nejprve zavoláme WriteStartElement("ahoj") a hned nato zavoláme WriteAttributeString("b", "nazdar"), vypíše se toto: <ahoj b="nazdar">. A pak máme ještě metodu WriteEndElement, která zapíše koncový tag.
Pomocí těchto 4 metod vygenerujeme náš požadovaný dokument. Napíšeme tedy tag <objednavka>, dovnitř <zakaznik>2567</zakaznik> a tag <polozky>, do nějž vypíšeme všechny položky ze slovníku a protože jsme hned po každé položce zavolali WriteEndElement, každá položka se hned uzavřela, takže položka vypadá např. takto: <polozka id="a42" mnozstvi="4" />. Správně bychom měli zavolat ještě WriteEndElement, a to dokonce dvakrát, protože musíme uzavřít jak element polozky, tak element objednavka. Není to ale nutné, pokud zavoláme WriteEndElement, uzavřou se všechny neuzavřené tagy automaticky.
Pak jen stačí zavolat Close, aby se dokument zapsal do souboru a tento soubor mohl být uzavřen. Úplně na závěr spustíme vygenerovaný XML soubor, který by se měl otevřít ve webovém prohlížeči. Uvidíte ihned, co se vygenerovalo. Je to přesně to, co jsme chtěli.
Závěrem
V tomto článku jsme si ukázali základní použití tříd XmlDocument a XmlTextWriter. XML dokumenty mohou obsahovat spoustu dalších věcí (namespaces), můžeme s nimi provádět různé operace (transformace nebo kontrola podle schémat), ale to je již velmi pokročilé téma. Pro běžné úkony vám bude stačit to, co je v tomto článku.